ボイスターの仕組み
コンピュータで、テキストデータを指定(入力)すると、音声として読上げてくれる音声合成ソフト(いわゆる「読上げソフト」)というものがあります。 昔はいかにもロボット的な音声でしたが、最近はかなり自然な人間の声に近いものが色々と出てきています。中には、歌を歌ってくれるものも出てきました。
自分の声ソフトウェア「ボイスター」は、このような音声合成ソフトの一種です。
ボイスターの特徴は、特定個人(本人)の声で 文字を読み上げてくれることです。
つまり、あなたの声・あの人の声を、パソコンが作ってくれます。
「あの声」「あの口調」を、あらたに作りだせること、
これがボイスターの、他にはない 最大の特徴です。
そこでボイスターの最大の特徴は、他の どの音声合成ソフトウェアよりも、「生声品質」にこだわっていることです。
その実現のために、あらかじめその人の声で、ある程度の文章を読んでいただき、その声を録音する必要があります。基本的には、最小限の量で、最大限の声の組み合わせをカバーするような文章(音素バランス原稿)を読んでいただきます。この声から、その人の「音声データベース」というものを作ります。この音声データベースを作れば、どんな言葉でも、その人の声のメッセージをパソコンが作ります。
この「音声データベース」というのは、収録したその人の音声を、言語的・音響的に分析し、音声合成をする際に最適な組み合わせを得られるようにしたものです。
●ボイスターの、録音していないフレーズの声をあらたにつくり出すしくみの概要
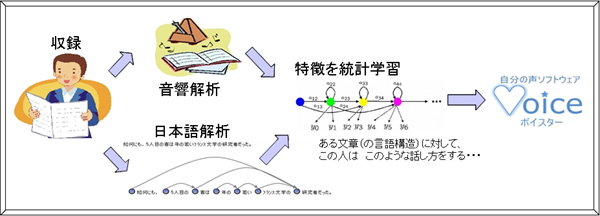
図:2013年日本言語聴覚学会全国大会資料から抜粋
録音音声から 『この人なら、このように読む』 という特徴を、音素のつながりすべてにわたり記録・整理
音声合成時には、以下の2つの処理を、パソコンの力をフルに利用して声をつくる
入力された文構造から録音音声を再現する 「声質」 「口調」 を推定。
推定した 「声質」 「口調」にあう、声の断片を録音音声全体から探し出し(大規模組合せ最適化問題を解く)、それらをつなぎあわせて合成音声を作成
少しわかりやすく説明すると、録音した声を、音素(「ア」とか「イ」とか)と呼ばれる、おおよそローマ字に相当する細かい区間に分割したうえで、 日本語の文構造に沿ってそれらを整理・保存します。
単純に「ア」といっても、その人の「ア」だけでも、音の高さやその変化のしかた、音の長さなど、 ちょっとした違いによって、何百、何千という沢山の種類の音声があります。それらの1つ1つの音が、どのような文脈で発話されたものかを記録しておくことで、 音声を合成する際には、その細かい沢山の「ア」の中から最適なものをコンピュータを使って選び出すことができるようになります。この1つ1つの音を、 全体的にみて最もきれいに繋がる組み合わせを見つけ出すことによって、一連の文章に対応する「あらたな声」をうみ出しています。
このように、ボイスターの合成音は、細かくみれば、すべて、その人が実際に発声した声、そのものなのです。そのため、 なかなか数学的な特徴として捕らえることが困難な、個人の声の特徴も、再現性が高くなっているのです。
なんとなく関西風のイントネーションだったり、その人にしかない特徴的な声だったり、ほのぼのとおっとりした声だったり・・・というような、 その人の声の持つ「雰囲気」(本人性)を自然な感じで再現できる点が最も大きなポイントの音声合成ソフトウェア、これが「ボイスター」なのです。
現在、ボイスターは、手術等で声を失われた方が、術後の音声コミュニケーションツールとしてご利用して頂くケースが中心です。
そのため、チャット風にテキストを入力できるようなユーザインタフェースにも工夫を続けています。「自分の声で、語りかける装置」として、 より良いものになるよう、様々な工夫を日々、続けています。